





摘要
提出的2019冠状病毒病(COVID-19)预后模型的数量正在迅速增长,但尚不清楚是否有任何模型适合广泛的临床实施。
我们在最终诊断为COVID-19的连续入院成人中,通过活体系统评估,独立地从外部验证了候选预后模型的性能。我们根据原始描述重建候选模型,并使用入院时测量的预测器评估其原始预期结果的表现。我们评估了区别性、校正性和净收益,与默认的治疗所有患者和不治疗患者的策略进行了比较,并与单变量分析中最具区别性的预测因素进行了比较。
我们在411名COVID-19患者中测试了22个候选预后模型,其中180人(43.8%)和115人(28.0%)分别达到了临床恶化和死亡率的终点。受试者工作特征(AUROC)曲线下的最高区域由预测24小时内病情恶化的NEWS2评分(0.78,95% CI 0.73-0.83)和预测入院后14天内病情恶化的新模型(0.78,95% CI 0.74-0.82)实现。最具鉴别性的单变量预测因子是入院时房间空气中的氧饱和度(AUROC 0.76, 95% CI 0.71-0.81)和住院死亡率的年龄(AUROC 0.76, 95% CI 0.71-0.81)。在一定的阈值概率范围内,没有任何预后模型显示出始终高于这些单变量预测器的净收益。
入院时室内空气氧饱和度和患者年龄分别是COVID-19住院成人病情恶化和死亡率的有力预测指标。这里评估的预后模型都没有为这些单变量预测因子的患者分层提供增量价值。
摘要
在COVID-19住院成人患者中,房间空气的氧饱和度和患者年龄分别是病情恶化和死亡率的有力预测指标。本研究评估的22个预后模型中,没有一个为这些单变量预测因子增加增量值。https://bit.ly/2Hg24TO
简介
2019冠状病毒病(COVID-19)由严重急性呼吸综合征冠状病毒-2 (SARS-CoV-2)引起,可导致从无症状感染到危重疾病的一系列疾病。据报告,在入院的患者中,COVID-19的死亡率为21%-33%,其中14%-17%需要入住高依赖或重症监护病房[1- - - - - -4].SARS-CoV-2的传播呈指数级激增,加上受影响人群中疾病的严重程度,对卫生服务构成重大挑战,有可能超出资源能力[5].因此,在送往医院时就需要迅速和有效的分诊,以促进充分分配资源,并确保对病情恶化风险较高的患者进行适当的管理和监测。预后模型可能对新兴药物治疗的患者分层有额外的价值[6,7].
因此,全球都对开发COVID-19预测模型感兴趣[8].其中包括旨在预测COVID-19诊断的模型和旨在预测疾病结果的预后模型。在撰写本文时,一项实时系统综述已经对COVID-19的145种诊断或预后模型进行了分类[8].使用专门为预测建模研究开发的质量评估工具对这些模型进行的批判性评估表明,候选模型报告得很少,而且对其报告的性能存在很大的偏差和高估风险[8,9].然而,在未选择的数据集中,缺乏对候选预后模型的独立评价。目前尚不清楚这些提出的模型在实践中表现如何,也不清楚是否有任何模型适合广泛的临床实施。我们的目的是通过系统地评估在单一中心最终诊断为COVID-19的连续住院患者中提出的预后模型的表现,并使用在入院点测量的预测因子,以弥补这一知识差距。
方法
候选预后模型的识别
我们使用一项已发表的活系统综述来确定截至2020年5月5日在PubMed、Embase、Arxiv、medRxiv或bioRxiv中索引的所有COVID-19候选预后模型,而不管潜在研究质量如何[8].我们纳入了旨在预测COVID-19患者临床恶化或死亡率的模型。我们还纳入了临床实践中常用的预后评分[10- - - - - -12],但并不是专门为COVID-19患者开发的,因为临床医生也可以考虑使用这些模型来帮助COVID-19患者进行风险分层。对于每个确定的候选模型,我们从原始出版物中提取预测变量、结果定义(包括时间范围)、建模方法和最终模型参数。我们联系了作者以获得更多的信息。我们排除了基础模型参数无法公开获取的分数,因为我们无法重建它们,同时也排除了包含预测因子的模型,这些模型在我们的数据集中无法获得。后者包括需要计算机断层扫描成像或动脉血气采样的模型,因为这些调查没有在我们中心未选定的COVID-19患者中常规进行。
研究人群
我们的研究是根据透明报告的个体预后或诊断多变量预测模型(TRIPOD)指导的外部验证研究[13].我们纳入了伦敦大学学院医院在2020年2月1日至4月30日期间最终诊断为聚合酶链反应确诊(包括所有样本类型)或临床诊断为COVID-19的连续成年人。由于我们试图使用入院时的数据来预测预后,我们排除了从其他医院转来的患者和医院获得性COVID-19患者(定义为入院后5天发送的第一个PCR拭子>,作为临床怀疑出现SARS-CoV-2感染的代理)。在没有替代诊断的情况下,临床COVID-19诊断是在传染病专家使用临床特征、实验室结果和放射学表现手工回顾记录的基础上做出的。在研究期间,在临床怀疑的基础上进行PCR检测,没有常规进行SARS-CoV-2血清学调查。
感兴趣的数据源和变量
数据是通过直接从电子健康记录中提取,辅以人工整理的方式收集的。数据集中感兴趣的变量包括人口统计学(年龄、性别、种族)、共病(通过手工记录复查确定)、临床观察、实验室测量、放射学报告和临床结果。每张胸片都由一名放射科医生报告,在提出要求时,向该放射科医生提供了调查指征的简短摘要,反映常规临床情况。胸片分级采用英国胸部成像学会标准,并采用改良版的肺水肿影像学评估(RALE)评分[14,15].对于每个预测者,测量记录作为常规临床护理的一部分。在可进行连续测量的情况下,我们包括了最接近就诊时间的测量,就诊和测量之间的最大间隔为24小时。
结果
对于以ICU住院或死亡,或进展到“严重”COVID-19或死亡作为复合终点的模型,我们使用复合“临床恶化”终点作为主要终点。我们将临床恶化定义为开始通气支持(持续气道正压、无创通气、高流量鼻导管供氧、有创机械通气或体外膜氧合)或死亡,相当于世界卫生组织(WHO)临床进展评分≥6 [16].这个定义不包括标准的氧疗法。我们没有对1)呼吸支持的最短持续时间或2)入院与预后之间的间隔时间施加任何时间限制。考虑到医院呼吸管理算法可能有很大差异,这一综合结果的基本原理是使终点在中心之间更具有普遍性。根据支持水平(而不是病房设置)确定结果,还确保在大流行的情况下是适当的,因为由于资源限制,通常只在ICU环境中考虑的治疗可能在其他环境中实施。当模型在其原始描述中指定了其预期的时间范围时,我们在主要分析中使用该时间点以确保模型校准的无偏性评估。在没有指定预期时间范围的情况下,我们对模型进行评估,以适当预测住院恶化或死亡率。所有恶化和死亡事件包括在内,无论其临床病因。
对参与者进行临床随访直到出院。我们通过交叉检查国民健康服务(NHS)脊柱记录来确定出院后报告的死亡,从而延长出院后的随访时间,从而确保所有参与者的>30天随访。
统计分析
对于分析中包含的每个预后模型,我们根据作者的原始描述重建模型,并试图根据我们对其原始预期终点的逼近来评估模型的鉴别和校准性能。对于提供在线风险计算工具的模型,我们通过交叉检查我们的预测与基于web的工具为参与者的随机子集生成的预测来验证我们的重构模型与原始作者的模型。
对于所有模型,我们通过量化接受者工作特征曲线(AUROC)下的面积来评估识别率[17].对于提供结果概率评分的模型,我们通过预测的可视化校准来评估校准与使用loess平滑图和量化校准斜率和大范围校准(CITL)观察风险。一个完美的校准斜率应为1;斜率<1表示风险估计过于极端,而斜率>1表示风险估计不够极端。理想的CITL为0;CITL>0表示预测系统地过低,而CITL<0表示预测过高。对于基于分数的模型,我们通过绘制模型分数来评估校准与实际的结果比例。对于提供概率估计的模型,但在模型截距不可用的情况下,我们通过使用模型线性预测器作为偏移项时计算截距,将模型校准到我们的数据集,从而实现了完美的CITL。根据定义,这种方法高估了相对于CITL的校准,但允许我们检查数据集中的校准斜率。
我们还通过计算与时间相关的auroc(具有累积敏感性和动态特异性),评估了每个候选模型对以下标准化结果的区分性:1)临床恶化的复合终点和2)从入院起(7天、14天、30天和住院期间的任何时间)范围内的死亡率[18].这种分析的基本原理是协调端点,以便在候选模型之间进行更直接的鉴别比较。
为了进一步评估候选预后模型的性能,我们计算了数量有限的被认为是最重要的单变量预测因子的auroc先天的根据临床知识和现有数据,预测我们的临床恶化和死亡率的复合终点(7天、14天、30天和住院期间的任何时间)。的先天的本分析中涉及的预测因素包括年龄、临床虚弱程度、在房间空气中呈现时的氧饱和度、c反应蛋白水平和绝对淋巴细胞计数[8,19].
决策曲线分析允许评估候选模型的临床效用,并依赖于模型辨别和校准[20.].我们进行了决策曲线分析,以量化每种模型在预测一系列风险下的原始预期终点时所获得的净效益:效益比[20.].在这种方法中,风险:收益比类似于统计模型的切点,高于该切点,干预或治疗将被认为是有益的(被视为“阈值概率”)。净效益计算为sensitivity×prevalence -(1 -特异性)×(1 -患病率)×w,其中w为阈值概率的比值,患病率为经历结果的患者比例[20.].我们计算了一系列临床相关阈值概率的净收益,范围从0到0.5,因为任何给定的干预措施的风险:收益比可能不同。我们将每个候选模型的效用与治疗所有患者和不治疗患者的策略进行了比较,并酌情与医院内临床恶化或死亡率的最佳单变量预测器进行了比较。为了确保公平,在基于多变量概率的模型、积分模型和单变量预测器之间进行面对面的净效益比较,我们校准了验证数据集,以进行决策曲线分析。以候选模型线性预测因子为唯一预测因子的逻辑回归模型将基于概率的模型重新校准到验证数据。当使用指数模型减去1)治疗所有患者和2)使用最具鉴别力的单变量预测器时,我们计算“δ”净收益为净收益。决策曲线分析采用rmdaR的包[21].
我们使用链式方程的多重归责处理缺失数据[22],使用老鼠R的包[23].最终预后模型中的所有变量和结果均纳入归责模型,以确保相容性[22].共生成了10个估计数据集;采用鲁宾规则将歧视、校准和净效益指标汇集在一起[24].
所有的分析都在R(版本3.5.1;R统计计算基金会,维也纳,奥地利)。
敏感性分析
我们重新计算了每个候选模型的鉴别和校准参数,使用1)完整的病例分析(考虑到一些模型的大量缺失),2)排除无pcr确认的SARS-CoV-2感染的患者,3)排除到达医院后4小时内出现临床恶化结果的患者。我们也检查了非线性先天的使用限制三次样条的单变量预测器,有三个节。最后,我们估计了鉴别的乐观度和校准参数先天的使用自引导(1000次迭代)的单变量预测器,使用rmsR的包[25].
伦理批准
预先指定的研究方案得到了东米德兰-诺丁汉2研究伦理委员会的批准(REF: 20/EM/0114;ira: 282900)。
结果
候选预后模型的总结
我们确定了37项描述预后模型的研究,其中19项研究(包括22个独特的模型)符合纳入条件(补充图S1而且表1).其中,有5个模型不是专门针对COVID-19的,而是作为急诊科参与者的预后评分开发的[27],住院病人[12,44],怀疑感染的人士[10]或社区获得性肺炎[11].在专门为COVID-19开发的17个模型中,大多数(17个中的10个)使用源自中国的数据集开发。总的来说,除了一项使用社区数据发现模型的研究外,发现人群包括住院患者,并且与当前验证人群相似[28],另一个则使用了模拟数据[29].在22个模型中,共有13个使用基于分数的评分系统来得出最终模型得分,其余使用逻辑回归建模方法来得出概率估计。在22个预后模型中,共有12个模型的主要目的是预测临床恶化,而其余10个模型仅寻求预测死亡率。在指定的情况下,预后的时间范围为1至30天。未纳入当前验证研究的候选预后模型总结在补充表S1.
研究队列概述
在研究期间,521名最终诊断为COVID-19的成年人入院,其中411人符合纳入的资格标准(补充图S2).队列的中位年龄为66岁(四分位范围(IQR) 53-79岁),大多数为男性(411人中有252人;61.3%)。表2显示了研究队列的基线人口统计数据、共病、实验室结果和临床测量,其中大多数(411人中370人;90.0%)有PCR确诊的SARS-CoV-2感染(370人中有315人(85.1%)在第一次PCR检测中呈阳性)。共有180名参与者(43.8%)达到了临床恶化的终点,115名参与者(28.0%)达到了死亡率的终点,超过了外部验证研究推荐的100个事件的最低要求[45].临床恶化和死亡的风险自入院以来随时间的推移而下降(中位天数至恶化1.4 (IQR 0.3-4.2);死亡天数中位数6.6 (IQR 3.6-13.1);补充图S3).计算22个预后模型评分所需的大部分变量在绝大多数参与者中都是可用的。然而,411例中只有183例(44.5%)检测到乳酸脱氢酶,411例中只有153例(37.2%)检测到d -二聚体,导致需要这些变量的模型显著缺失(补充图S4).
对最初主要结果的预后模型的评估
表3在适当的情况下,显示22个评估预后模型在初级多重归责分析中的鉴别和校准指标。预测24小时内恶化的NEWS2评分(0.78,95% CI 0.73-0.83)和预测14天内恶化的Carr“final”模型(0.78,95% CI 0.74-0.82)获得了最高auroc。目前在常规临床实践中使用的其他预后评分中,CURB65对30天死亡率的AUROC为0.75 (95% CI 0.70-0.80),而qSOFA对住院死亡率的AUROC为0.6 (95% CI 0.55-0.65)。
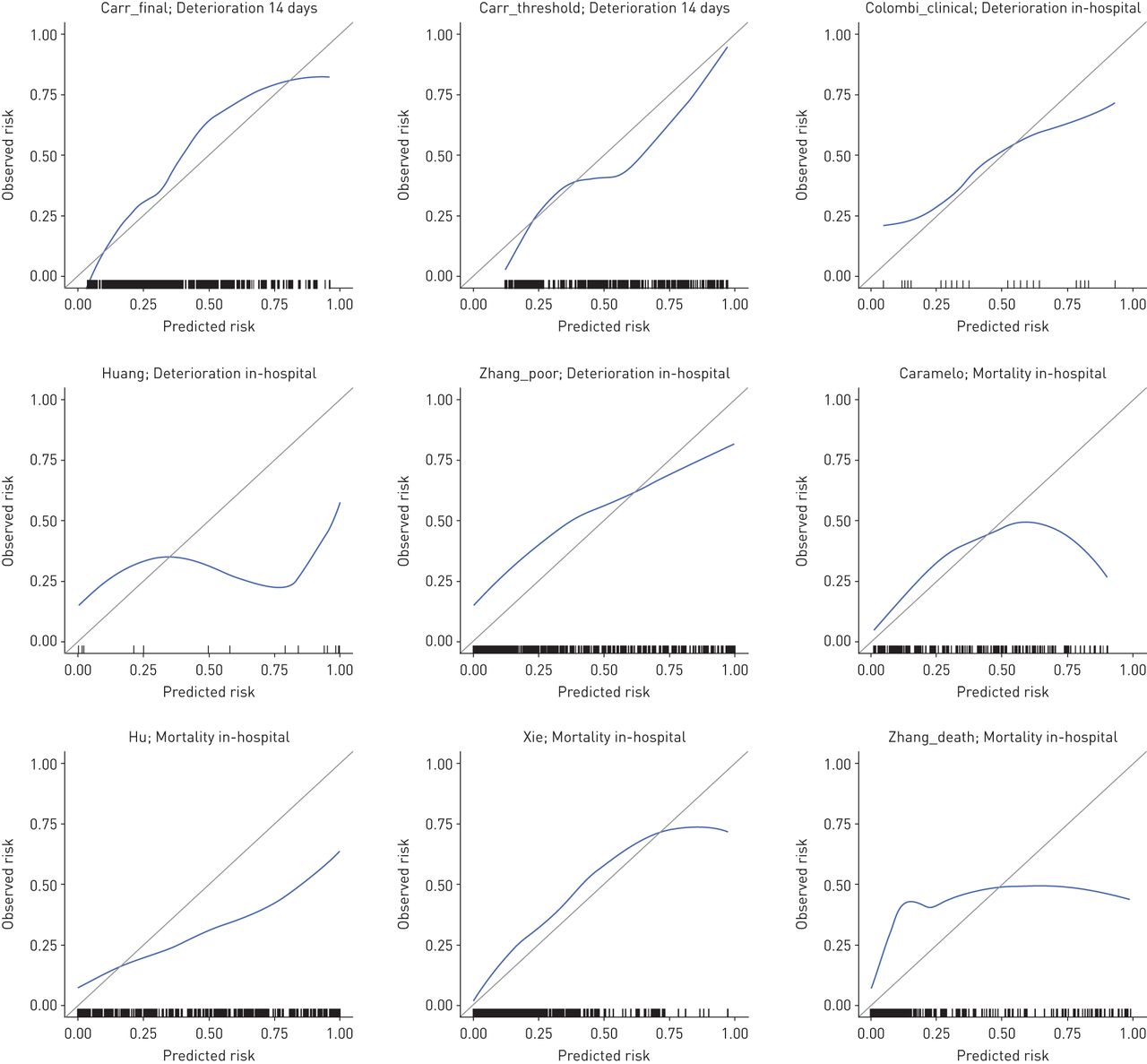
对于所有提供恶化或死亡率的概率评分的模型,校正在视觉上似乎很差,有过拟合的证据以及系统性的风险高估或低估(图1).补充图S5显示了基于分数的预后模型与实际风险之间的关联。除了展示了合理的区分,NEWS2和CURB65模型分别展示了评分与24小时实际恶化概率和30天死亡率之间的近似线性关联。
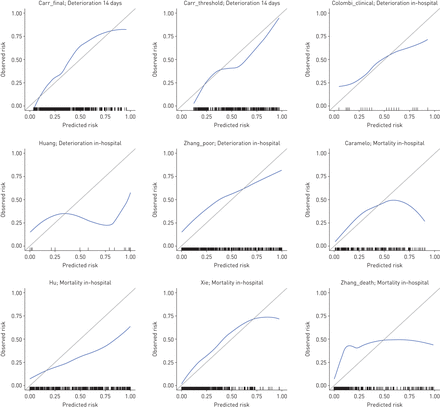
预测结果概率的预后模型校准图。对于每个图,蓝线表示来自堆叠的多个计算数据集的loess平滑校正曲线,地毯图表示数据点的分布。没有模型拦截可用于Caramelo或Colombi“临床”模型;使用模型线性预测器作为偏移量项,将这些模型的截距校准到验证数据集。每个模型的主要结果显示在图的子标题中。
候选模型的时间依赖性判别和先天的标准化结果的单变量预测因子
接下来,我们试图比较这些模型在不同时间范围内对临床恶化和死亡率的区分性,并以与COVID-19不良结果相关的预选单变量预测因素为基准[8,19].我们重新计算了每个结果的时间依赖性auroc,并按结果的时间范围分层(补充图S6和S7).这些分析表明,auroc总体上随着时间范围的增加而下降。入院时室内空气周围氧饱和度是住院情况恶化的最强预测因子(AUROC 0.76, 95% CI 0.71-0.81),而年龄是住院死亡率的最强预测因子(AUROC 0.76, 95% CI 0.71-0.81)。
决策曲线分析评估临床效用
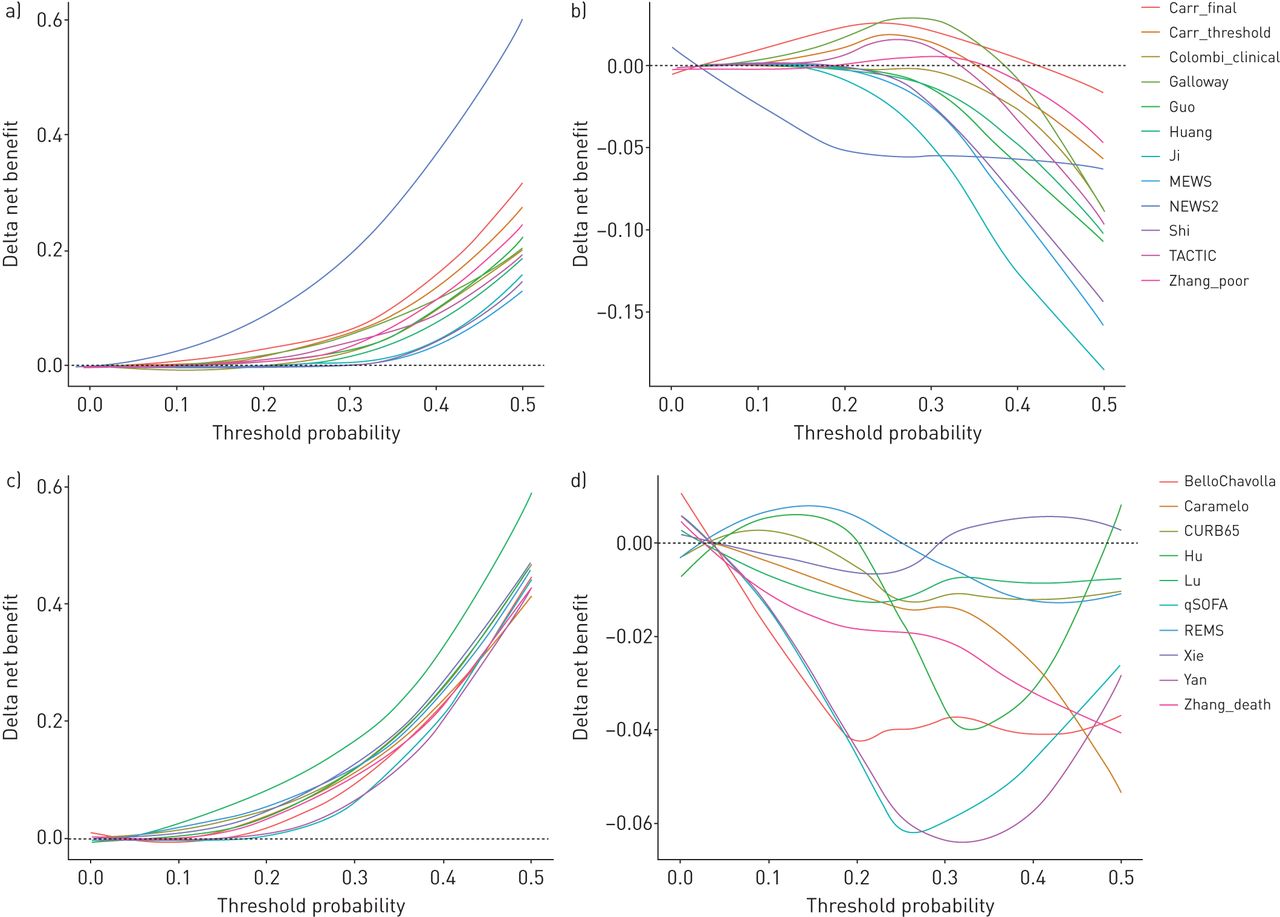
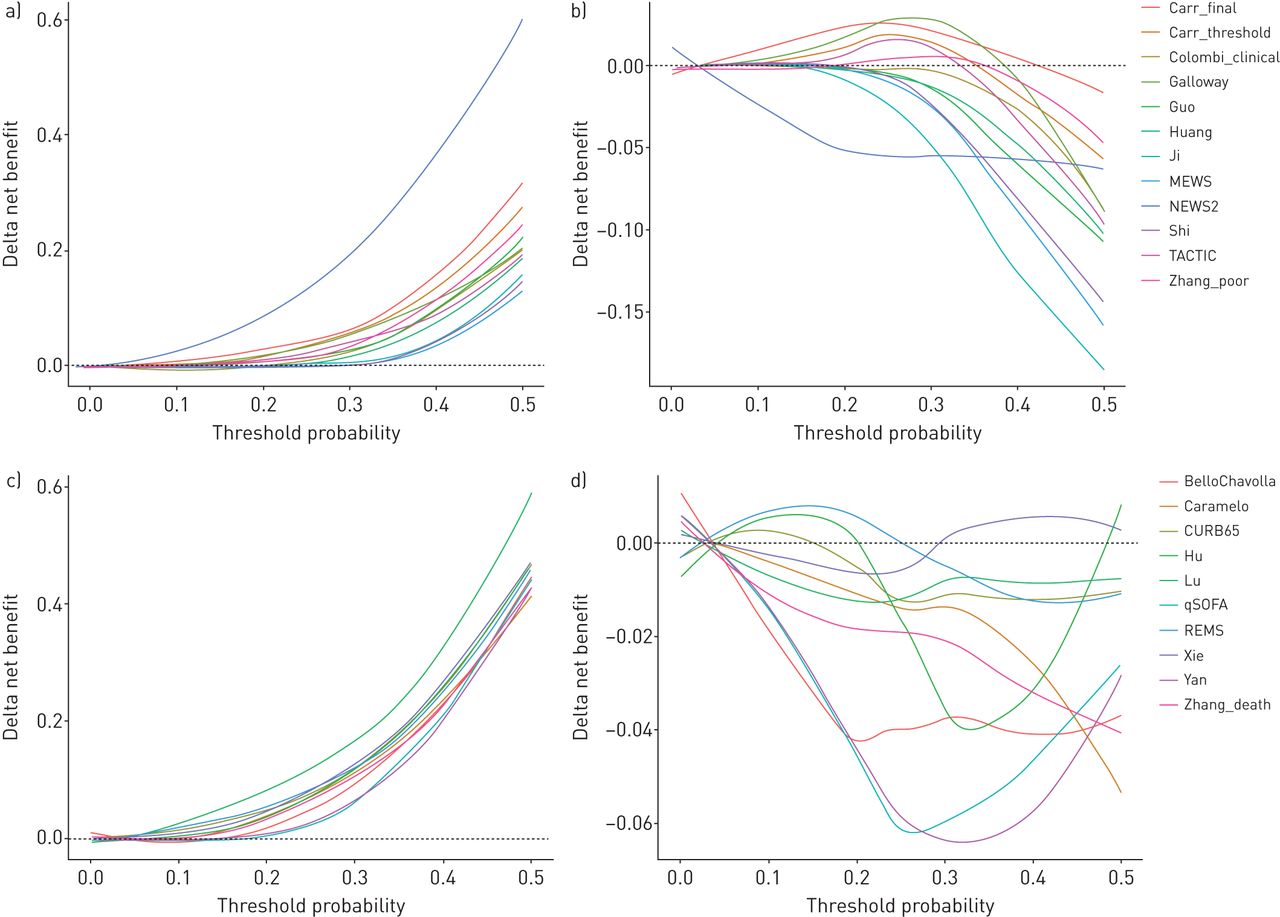
我们将每种预后模型的净收益(为其最初预期终点)与治疗所有患者、不治疗患者和使用最具鉴别力的单变量预测因子(即。空气含氧饱和度)或死亡率(即。患者年龄)进行分层治疗(补充图S8).尽管所有的预后模型都显示出比在较高阈值概率范围内治疗所有患者更大的净收益,但在阈值概率范围内,这些模型中没有一个显示出持续大于最具鉴别力的单变量预测器的净收益(图2).
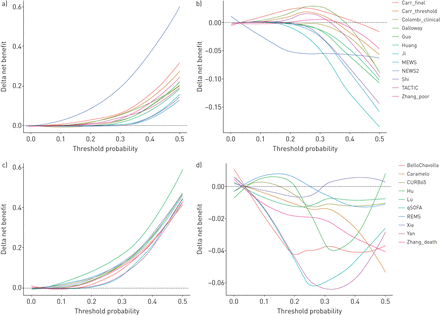
决策曲线分析显示,与治疗所有患者和最佳单变量预测器相比,每个候选模型的δ净收益。a)劣化模型与对所有;B)劣化模型与周围氧饱和度(年代阿宝2)单独播出;C)死亡率模型与对所有;D)死亡率模型与年龄。对于每个分析,端点是索引模型的原始预期结果和时间范围。在分析过程中,每个候选模型和单变量预测器都根据验证数据进行校准,以实现公平的正面比较。Delta净效益计算为使用指数模型时的净效益减去1)治疗所有患者和2)使用最具鉴别力的单变量预测器时的净效益。最具鉴别力的单变量预测因子是录取年代阿宝2以室内空气为恶化模型,以病人年龄为死亡模型。Delta净效益用loess平滑表示。黑色虚线表示阈值以上的指数模型比比较器有更大的净效益。每个候选模型的单独决策曲线见补充图S8.
讨论
在这项针对连续因COVID-19住院成人的观察队列研究中,我们系统评估了22种COVID-19预后模型的性能。其中包括专门为COVID-19开发的模型,以及大流行前常规临床使用的现有评分。对于临床恶化或死亡率的预测,auroc范围为0.56-0.78。NEWS2在24小时间隔内的恶化预测方面表现得相当不错,AUROC为0.78,而Carr“最终”模型[30.AUROC也为0.78,但倾向于系统性低估风险。推导出恶化或死亡结果概率的所有covid - 19特定模型均显示校准不良。我们发现,室内空气周围氧饱和度(AUROC 0.76)和患者年龄(AUROC 0.76)分别是预测住院恶化和死亡率的最具鉴别性的单变量。这些预测指标还有一个额外的优点,即在向医院报告时可以立即得到。在决策曲线分析中,依赖于模型识别和校准,没有任何预后模型显示出的临床效用始终大于使用这些单变量预测器来通知决策。
虽然以前的研究主要集中于新模型的发现,或对有限数量的现有模型进行评估,但据我们所知,这是第一项系统评估已确定的COVID-19候选预后模型的研究。我们使用了一个全面的生活系统回顾[8]识别符合条件的模型,并试图根据原始作者的描述重构每个模型。然后,在可能的情况下,我们根据预期结果和时间范围,使用推荐的外部验证方法,包括甄别、校准和净效益评估[17].我们采用了稳健的电子健康记录数据捕获方法,并辅以人工筛选,以确保高质量数据集,并包括符合我们资格标准的未选定的连续COVID-19病例。我们采用了死亡率和临床恶化的可靠结果衡量标准,并与世卫组织临床进展量表相一致[16].
目前研究的一个弱点是,它是基于来自单一中心的回顾性数据,因此不能评估模型性能的设置之间的异质性。其次,由于常规收集的数据的局限性,每个模型的预测变量可用于不同数量的参与者,需要乳酸脱氢酶和d -二聚体测量的模型有很大比例的缺失。因此,在我们的初步分析中,根据多变量预测模型开发和验证的建议,我们进行了多重归责[46].在完整的个案敏感性分析中,结果是相似的,因此支持我们的结果的稳健性。未来的研究将受益于标准化的数据采集和实验室测量,以尽量减少预测遗漏。第三,我们的数据中有很多模型无法重构。对于一些模型,这是由于我们的数据集中缺少预测因子,例如那些需要计算机断层扫描成像的模型,因为目前不建议对疑似或确诊的COVID-19患者进行ct成像[15].我们也无法包括那些无法公开获得参数的模型。这强调了在多变量预测模型中严格遵守报告标准的必要性[13].最后,我们在本研究中仅使用入院数据作为预测因子,因为大多数预后评分旨在预测入院时的结果。然而,我们注意到,一些评分是为住院患者动态监测而设计的,NEWS2显示了在24小时间隔内病情恶化的合理区分,如最初预期的那样[44].未来的研究可能会在使用这种动态测量时集成串行数据来检查模型性能。
尽管全球对寻找COVID-19的预后模型非常感兴趣,但我们的研究结果表明,本研究评估的COVID-19特异性模型目前都不能推荐用于常规临床使用。此外,虽然一些评估模型不是针对COVID-19的,但它们是常规使用的,可能对住院患者有价值[12,44],怀疑感染的人士[10]或社区获得性肺炎[11],在COVID-19患者中,没有比最强的单变量预测因子更具有临床效用。我们的数据显示,入院时的室内空气氧饱和度是临床恶化的一个强有力的预测指标,并建议在未来的研究中对其进行评估,以分层住院患者管理和远程社区监测。我们注意到,当前研究评估的所有COVID-19新预后模型都来自单中心数据。未来的研究可能寻求汇集来自多个中心的数据,通过个体参与者数据元分析,在异质性人群中稳健地评估现有和新兴模型的性能,并开发和验证新的预后模型[47].这样的方法将允许评估研究之间的异质性和候选模型可能的普遍性。发现人群是模型实施的目标人群的代表,包括未选择的队列,这也是必要的。此外,我们强烈主张按照TRIPOD标准(包括建模方法、所有模型系数和标准误差)进行透明报告,并对结果和时间范围进行标准化,以促进对模型性能和临床效用的持续系统评估[13].
我们得出结论,房间空气的基线氧饱和度和患者年龄分别是恶化和死亡率的强预测因子。当使用入院数据时,本研究中评估的预后模型均未为这些单变量预测因子的患者分层提供增量价值。因此,没有一种评估的COVID-19预后模型可推荐用于常规临床实施。寻求开发COVID-19预后模型的未来研究应考虑整合多中心数据,以增加研究结果的普遍性,并应确保以现有模型和更简单的单变量预测器为基准。
补充材料
可共享的PDF
脚注
UCLH COVID-19报告小组由以下人员组成,他们作为非作者贡献者参与了数据管理:Asia Ahmed, Ronan Astin, Malcolm Avari, Elkie Benhur, Anisha Bhagwanani, Timothy Bonnici, Sean Carlson, Jessica Carter, Sonya Crowe, Mark Duncan, Ferran Espuny-Pujol, James Fullerton, Marc George, Georgina Harridge, Ali Hosin, Rachel hubbq, Prem Jareonsettasin, Zella King, Avi Korman, Sophie Kristina, Lawrence Langley, Jacques-Henri Meurgey, Henrietta Mills, Alfio Missaglia, Ankita Mondal, Samuel Moulding, Christina Pagel, Liyang Pan, Shivani Patel, Valeria Pintar,Jordan Poulos, Ruth Prendecki, Alexander Procter, Magali Taylor, David Thompson, Lucy Tiffen, Hannah Wright, Luke Wynne, Jason Yeung, Claudia Zeicu, Leilei Zhu。
作者贡献:R.K. Gupta和M. Noursadeghi构思了这项研究。R.K.古普塔进行了分析,并撰写了手稿的初稿。所有其他作者都对数据收集、研究设计和/或解释做出了贡献。所有作者在投稿前都经过了严格的评审和认可。通讯作者证明,所有列出的作者都符合作者标准,没有其他符合标准的作者被遗漏。UCLH 2019冠状病毒病报告小组的成员对数据整理做出了贡献,并且是本研究的非作者贡献者/合作者。
本文的补充资料可从www.qdcxjkg.com
监管机构批准本研究的条件排除了开放获取数据共享,以最大限度地降低通过细粒度个人健康记录数据识别患者的风险。188滚球软件根据GDPR的规定,作者将考虑将特定的数据共享请求作为学术合作的一部分,并根据伦理批准和数据传输协议。
支持声明:该研究由国家卫生研究所(drf - 2018-11-2 - st2 -004至R.K. Gupta;nsf - si -0616-10037授予I. Abubakar)、Wellcome信托基金(207511/Z/17/Z授予M. Noursadeghi),并得到了国家卫生研究所(NIHR)伦敦大学学院医院(UCLH)生物医学研究中心(BRC)的支持,特别是NIHR UCLH/伦敦大学学院(UCL) BRC临床和研究信息部的支持。本文是由国家卫生研究所支持的独立研究。本文仅代表作者个人观点,不一定代表NHS、国家卫生条例或卫生和社会保障部的观点。资助者在研究设计中没有任何作用;数据的收集、分析和解释;在写报告时;或者决定将文章提交发表。本文的资助信息已存入Crossref基金管理人登记处.
利益冲突:M. Marks没有什么可透露的。
利益冲突,t.h.塞缪尔斯没什么可透露的。
利益冲突:A.卢因特尔没有什么可透露的。
利益冲突:t·兰普林没什么可透露的。
利益冲突:乔杜里没有什么可透露的。
利益冲突:M. Quartagno没有什么要透露的。
利益冲突:A. Nair报告了来自ai丹斯BV的非财政支持和来自NIHR伦敦大学学院生物医学研究中心的赠款,在提交的工作之外。
利益冲突:M. Lipman没有什么要透露的。
利益冲突:一、阿布巴卡尔没有什么可透露的。
利益冲突:M. van Smeden没有什么要透露的。
利益冲突:王w.k.没有什么可透露的。
利益冲突:B.威廉姆斯没有什么可透露的。
利益冲突:M. Noursadeghi在研究期间报告了威康信托基金和伦敦大学学院NHS信托基金国家卫生研究所生物医学研究中心的赠款。
利益冲突:R.K.古普塔没什么可透露的。
- 收到了2020年9月14日。
- 接受2020年9月17日。
- 版权所有©ERS 2020
此版本在知识共享授权许可4.0的条款下发布。











{kind=link}
{kind=link}
{kind=link}
{kind=link}